
Are you a regular user of the popular software version control system, git? If so, do you love it? If you do, then you are a perfect example of the miracle of neuroplasticity. Your brain – through an initially painful process – has grown new connections and adapted to a set of habits and associations that are twistedly unnatural in the scope of all tools created by homo sapiens.
metaphor
Consider the following clash of metaphors:
“pulling from upstream”, “fetch”, “cherry pick”, “filter branch”, “untracked”, “symlink”, “rebase”, “tag”, “HEAD”, “working copy”, “head”, “path”, “stash”, “clone”, “submodule”, “fast-forward”, “merge”, “origin/master”, “staging area”.
Unless you are a surrealist poet, you will have a hard time generating anything of value with these terms. Alas…software developers are generally not interested in spinning narratives or crafting metaphorical microworlds. Of course, many programmers are interested in designing intuitive, self-consistent language in their tools. This would be awesome if they didn’t suck at it so very badly. In the case of git, it’s original creator, Linus Torvalds, appears to have demonstrated the classic negligence of an anti-design geek who has no time for wordsmithing.
Here’s the problem: if you are designing command-line tools, then wordsmithing is all you’ve got. It’s all just language.
Elegance
I must admit: when someone sits down and explains how git works, and why it’s such a great concept, I see the light. These explanations are often accompanied by tree diagrams and arrows. This is encouraging.
And then I sit down and start using it. And the nightmare begins. All over again. Because the obscure language and cryptic behavior of git is impossible to remember, unless you use it every day. And who uses it every day? Git-lovers, of course. Their brains are soaking in the Koolaid from yesterday’s day on the job. There’s no mystery here.
Am I alone in my hate for git? Witness:
Here’s Mike Taylor on how opaque git can be, and why it is so confusing, especially to people who have not finished tying their brains into knots (i.e., they are still normal).
Here’s Steve Bennett, who says this about git: “What a pity that it’s so hard to learn, has such an unpleasant command line interface, and treats its users with such utter contempt.”
Here are some git-haters on Amplicate
Scott James Remnant sez: “I’ve had a few ex-boyfriends hang up on me before, and they were gits too.”
As I have always thought about version control systems in general: what is so very missing are good interactive visual tools that express the states and dynamics of a repository, and provide natural affordances. Mark Lodato is one of a small set of explainers making an attempt to turn this cryptic language-pretzel into something that we can wrap our brains (and eyes) around:
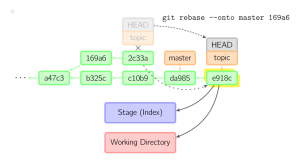
But I think it will take more than just good visual-interactive tools to make version control a natural, pleasant part of programming with a distributed team. It will take a cultural shift in software development society. The people who are best-suited to design effective development tools are the very ones who are confused by the current pathological state of affairs, or repelled by it, or never even learned to program in the first place. I can’t blame them.

I agree. In fact, it is not only word choice; some of the commands themselves have extremely confusing behavior. For example, “git checkout BRANCH FILE” reverts FILE to the version found in BRANCH, but “git checkout BRANCH” switches branches.
It is a shame that the command-line interface is so confusing, because the tool itself is really great. I get the impression that a significant number of the developers agree that the interface is bad but the standard argument against fixing these things is that there are so many existing users who already know how it works now. Sadly, there doesn’t seem to be a clear solution to this problem.
How is that confusing? If you want to checkout a single file from a branch, then that sees eminently sensible to me. If you want to checkout a whole branch, then that also sounds sensible.
How does Mercurial work for you?
Your conclusion is about version tracking in general, so I’d like to see how Mercurial feels for you.
I’m wondering the same thing. I’ve always asserted Mercurial was superior to Git, but just doesn’t have the following (yet).
(I actually use the hg-git extension for talking to almost all Git repositories.)
I agree. Most of these apparently confusing concepts are found in all DVCS. It takes a while to wrap your head around them; but once you do these concepts change the way you look at version control in a profound way.
I greatly enjoyed your post. I’m not one to ever leave comments, but I
felt really compelled to this time. I shared this on my twitter and
bookmarked your blog!
I’ve got a couple of blog posts about this topic too. :-)
A vocabulary update for git might be a good thing, but designing a good story that everyone can use is not easy.
One issue is that metaphors were never designed to be a good change management system.
Another issue is that decent analogies for one part of the system (we might do a ‘git retcon’ to replace ‘git rebase’) might conflict analogies for another part (perhaps ‘git study’ to replace ‘git fetch’ — or perhaps leaving ‘git fetch’ alone).
Anyways, if someone can put together a consistent vocabulary that “tells the git story” and also “represents the git model”, I would be impressed. Until then, I will simply note that learning to use any computer technology requires some time, and that software developers have an ultimate responsibility when we are in the context of authoring software.
I suggested renaming “git rebase –interactive” to “git retcon” on Twitter yesterday – great minds think alike :-) It’s a much better name, I think: just as with retcons in the comics world, you can alter how things happened in the past and have the resulting changes propagate through to the present, but (crucially) the old stories are still available for reference, even if they are no longer part of the current continuity.
The name of the non-interactive rebase program is, IMHO, fine: you take a sequence of commits and graft them onto a new base. Perhaps “git graft” or “git transplant” would be better, but “rebase” is pretty clear.
The short answer is that there should be several interfaces then, each appropriate to the activity “domain”. Trying to develop a “universal interface” is kind of like trying to develop a universal editor to everything. It does taxes, script writing and 3d modeling all in one!
It’s a dessert topping and a floor wax, by Jove.
Yes! I’ve been trying to teach Git to humanities scholars, professional metaphoristas, and the lack of any metaphorical consistency makes it very difficult for them (and anyone) to learn. What we need are literary scholars, rhetoricians, and historians to help design of command line applications–or help design a *humane* alternative.
One stopgap solution to the Git problems is Legit:
http://www.git-legit.org/
Git was actually always intended to be nothing more than a set of low level tools to manage an object database of commits, blobs and trees plus references (and communication between such constructs. The idea was that someone would build a real VCS on top those tools.
Before anyone had a chance to design a consistent UI the user base grew and people made various convenience scripts on top of these tools which eventually became a defacto interface to the underlying system. The result is a set of commands with no overarching design but rather independent functional fragments that solve various problems for various people (some of which evolved beyond that point). This leads to a confusing and inconsistent set of commands and various mixed metaphors.
The problem for someone new who wants to create a fresh UI with consistent commands and metaphors is that some of these defacto high level commands are very powerful. The developer must now either reinvent the high level commands (many of which are now binaries rather than shell scripts) or simply provide an interface wrapper around them which constrains them in various ways.
The answer to why git is hard to learn, confusing and inconsistent is history. The solution is to spend a long time reinventing various wheels into a consistent ‘vehicle’. The reason people don’t bother is that it’s good enough for their purposes: It’s broken, but not broken enough for me to do something about it.
This is one of the best explanations of the git situation I have ever seen. You nailed it.
I would almost agree.
But the story of the early wrappers (which were given up due to breakage – don’t ask me for the names, though…) also shows that the git developers did not care enough about backwards compatibility to make a wrapper possible.
They just cared enough about compatibility to keep the commands complex, but not enough to make a wrapper anything but a maintenance nightmare which broke regularly, because some git command changed syntax.
Can you come up with a decent comprehensive API for it?
It sounds like there’s room for one. Then someone could just make a script with a bunch of aliases that map to the more human friendly API first.
I’m too embedded in git to jump outside of it and designing a better interface, but can totally see your point and wouldn’t mind helping out implementing one with bash aliases or functions or something.
My answer to that is: Just use Mercurial. I know that that does not sound constructive to git users, but those (very vocal) git users are the very reason why no real wrapper exists today.
And you identify the problem quite nicely: “embedded it git” sounds much nicer than other ways of putting it, but it hits the nail. Sadly those aliases aren’t that simple, because they have to enable the user to get out of any situation without turning towards the regular git commands.
And they have to be used by core git maintainers to ensure that they keep working in future versions of git…
And my approach is to limit myself to a subset of git.
My problem with mecurial is a variation on the classic software tools problem: I’m using git because I am working with other people that use git, and mercurial does not support this.
Meanwhile, my problem with git is mostly that it has features which I have no use for.
So, my solution has been: I don’t use the parts that I have no use for.
For a longer term solution, I’d like to see git enhanced with a better subcommand vocabulary (but that has to wait until after it has been defined). And, once that exists, if it is complete enough, the ugly stuff can eventually be deprecated.
This approach might disappoint people in mercurial communities, but honestly: why do you care what I do? I frequently engage in activities that you have no interest in.
> I’m using git because I am working with other people that use git, and mercurial does not support this.
Actually it does:
http://hg-git.github.com/
It has completely replaced git usage for me. It’s not perfect: it gives a git flavour to an otherwise hg repo, but it works well enough.
> So, my solution has been: I don’t use the parts that I have no use for.
That works too, as long as nobody else uses parts you don’t understand either. This is rarely the case that other’s git usage impacts yours, but when they start using “features” like submodules or subtrees, then you have to start to understand yourself how they work too.
Thanks, I’ll try that. (For some reason I was under the impression that mercurial was a closed, proprietary system.)
For a while now I have been thinking about what would be possible if version control systems were embedded in our editors. I have developed a prototype VCS that I believe allows much more learning and understanding to take place from our code repos:
http://www.storytellersoftware.com
Please check how your blog looks like on a 1024×768, the follow popup covers the main text. Then start talking about UIs of other programs.
I think you’ve entirely missed the point.
And try a different browser. It looks fine in Chrome at that resolution.
Hey Tomasz, I hate the Follow popup as much as you do. But I have no control over that. Complain to WordPress. They have a lot of major UI issues.
I really can’t see how these metaphors aren’t apt…
fetch – fetching the objects and metadata from a branch or branches from a remote repository
pulling from upstream – fetching from a remote repository (upstream, in other words all the changes flow down the stream to you, colloquial expression), then merge in the objects you fetched
cherry pick – choose which changes to apply (“cherry pick” them, colloquial term)
filter branch – modify a branch’s history via filters
untracked – files that aren’t being tracked by the source control system
symlink – a symbolic link, not even a git concept.
rebase – replaying all the changes committed from one branch onto another. Literally taking one base, and changing the base of a branch. i.e. re-basing the branch
tag – marking (or “tagging”) a significant change in the repository
HEAD, head (note, mentioned twice by author) – a reference to the head of the revision history
working copy – the copy of a branch that you work on
path – really?
stash – you start working on some code, then you realise you want to change to another branch. So you stash away the working copy for later.
clone – cloning an existing repository so you can have your own to work on. That’s why it’s a DVCS
submodule – an external project from the main repository
fast-forward – when you merge a branch from another branch, git has the ability to forward the revision pointer quickly to the right point, see [1]
merge – merging changes
origin/master – the original repository. Convention.
staging area – also known as the “index”, basically the concept is that you checkout a branch into a directory (called the working copy, see above), then you commit any changes into a staging area, then you push the changes into the repository
Darn it… [1] refers to http://git-scm.com/book/en/Git-Branching-Basic-Branching-and-Merging
I think the OP’s point was that while each of these metaphors makes sense individually, there’s no overall consistency, and that this makes Git’s UI needlessly hard to learn.
Well the core of Git is very clean and simple. And by core I don’t mean commit, add push and pull; I mean the objects i.e. blob, tree, commit. The commands that git uses are very “high-level” compared to the core objects. The core is actually the best part of git; and because it’s so effective, git is literally the fastest DVCS out there. The commands used to interact with git thought were originally just plain shell scripts, which later became binary-compiled programs.
I agree! I have written an extensive comment below (currently held in the moderation queue) arguing that the solution to the OP’s problem is to abandon the search for a unifying metaphor and deal directly with the graph of commits. The command names are unfortunate and a tax on the memory (or the search engine), but they’re also superficial.
Neuroplasticity at its best!
Most funny. You call the creator of git a nerd who doesn’t know about what “real people” need (I guess if you ask around among the “real people as in random guys on the street”, even knowing what a dvcs is qualifies you as a nerd).
And, just in case someone wants to bring facts to the table, you presume some unnormal brain condition. I guess insults are easier than coping with arguments.
So to stay on your level: maybe your brain just lacks the intellectual capacity to comprehend the concept of git. “Holy shit, there’s a few technical terms that I have to remember. I can’t get my head around it!” Have fun should you ever try getting in any new field…
I agree completely! If they can’t spend time in learning these really important concepts which form the basis of every damn DVCS out there, just stay away from DVCS.
Plenty of people code occasionally! And many of them are very intelligent people. But unused knowledge slips out of the memory. I agree with the OP that while Git’s a great system for everyday users, it would be better for casual users if it didn’t require you to memorise so much vocabulary. A consistent metaphor (if one could be found) would greatly help with that.
Try explaining GIT to a non college educated non programmer. You’re lucky if they can reliably clone/pull/commit locally and to a single remote. It’s a huge risk and overhead generator in production.
We’ll stick with SVN and a GUI for real project work with contributors of all skill levels, GIT’s advanced features are awesome but exclusive and elitist.
The whole purpose of DVCS is the offline commit. A guy who doesn’t understand why he needs to commit when having no access to the central server shouldn’t even be allowed near a DVCS. Just stick to SVN or any other centralized VCS; commit only when you’re at work and just save your work to the file when server access is not available.
I think you have it completely backwards: The guy who does not understand why he needs offline commits is exactly the one who should have a DVCS: So that others can review (and fix) his changes before he breaks everything.
Sadly git is completely unsuited to those contributors.
But that’s not the fault of DVCS. It is the fault of git.
If you have trouble explaining git clone/pull/commit/push, how do you ever explain svn checkout/update/commit/lock/unlock? And honestly, with non college educated non programmers on your team, git is probably not the largest risk and overhead generator in your production grade projects.
SVN has it’s own share of “advanced” features and just like in git, you probably never need them. And for GUIs, there’s smartgit, tortoisegit and more that cover day to day work.
The problem is “git push”. That’s where the breakdown occurs.
“git push” pushes something that almost *never* matches the mental model held by anyone sane.
That is actually git’s default config. Personally, I like using: git config — global push.default current to make git push work right
I’m assuming that they don’t do anything other than check in and check out of a centralised repository. I’ll bet they don’t branch the code base, and I’m willing to bet my life on it that they don’t reemerge if they do branch their code!
Also willing to bet they don’t take their code hoe with them, or work on it away from the office.
On the one hand, I love Git, and so this makes me sad. On the other hand, you have a good point. I think the solution is to abandon metaphors and think directly about the (beautifully simple!) underlying graph representation – when I’m teaching people to use Git I always try to get them to focus on what’s happening to the graph rather than the names of the commands, which can always be looked up if necessary (Stack Overflow is great for this). Unfortunately we don’t have standard terms for a lot of the things Git does – what term would you use for “change the current branch to X, and update the working copy to the latest commit on branch X”? “Checkout”‘s a pretty opaque name for this, but I can’t think of a better one. It would be great if someone could find a consistent metaphor for a large fraction of what git does, for command-naming purposes if nothing else, but I’m not convinced one exists.
On visual tools: several exist already, and some of them are very useful. Do you know about the history viewer GitK and the cross-platform GUI tool git-gui? They’re not very pretty, but they’re IMHO very intuitive. I don’t use git-gui much any more, but I found it invaluable when I was learning Git, and I still use GitK all the time. If you’re on a Mac, you may prefer GitX, which provides the functionality of GitK and git-gui in a less ugly format.
On Mercurial: I tried it for a recent project, hoping to like it, but was rather disappointed. Git has a much better story for history-rewriting, a feature which I use heavily. Here’s a blog post I wrote, including my .hgrc – several default Mercurial settings are rather questionable, IMHO. You may also find Gary Bernhardt’s post about switching from Mercurial to Git helpful.
Hi Poz, sorry your message was held in queue – didn’t know it was there. WordPress is a pain sometimes: I had to make an obscure change deep in the settings because your comment had too many links. I set it so that a comment can have up to 8 links now before it is held as spam. Thanks.
Since you use history rewriting heavily, it was to be expected that Mercurial would give you pains.
This changes with mutable-hg, but that’s still in experimental stage: http://hg-lab.logilab.org/doc/mutable-history/html/
(I use it, but it is not perfectly polished, yet)
PS: I would not want to work without the record extension. But it would be daunting to casual users.
I’m glad I’m not the only person who thinks – even despite wonderful things like github making a huge difference – that git has an uneccessarily steep learning curve compared to other VCSs.
Ping! I notice that my long comment of 2013-01-30 10:20 is still held in the moderation queue after nearly two months. Any chance you could approve it, please?
I don’t see how it’s harder than learning to use any new programming language or toolkit, which is stuff developers do all the time. Yes, there’s complexity to it, but you could say the same for any other tool that programmers work with. Once you understand it, it’s an extremely elegant design.
I would have to disagree that all tools that programmers work with are complex. Some are more complex than others. Some are more well-designed than others. Some have steeper learning curves than others. One of my main points in writing the blog post was that once you are accustomed to a tool, you come to think of it as easy, and so you are no longer a valid critic. I think history will tell us whether git survives or whether another tool (or several other tools) will evolve to take its place. I can’t predict that. But I do hope that the evolution of software tools in general will continue in the direction of more natural and intuitive, so that human brains can do what they’re naturally good at and computers can continue to do what they’re naturally good at.
This is reminding me of Doug Engelbart’s comments on the design concept of “Easy to learn. Natural to use.” http://blog.arsmemoriae.com/?page_id=24 contrasted with concepts like “Worth learning” and “Efficient to use”.
The tricycle thing does not fit for me: You can start with training wheels and remove them once you are good enough with your bike to go without.
Those training wheels make the bike easy to learn, even though it would normally be horribly hard.
An alternative are those walk-bikes. My 2 year old son just started using one and he was overjoyed at getting it to move. Once he has his balance on a walking bike, he can move on to a real bike. But if he had to start with a real bike, he would be really frustrated again and again – possibly so frustrated that he would not like to start again.
Git does not offer the training wheels, and it has no way to get started again quickly after a break.
Git is like having a motorcycle with only one mode: Full speed. If you use it only from time to time, you have to check really carefully where you go before you start to be able to avoid crashing into a wall. And if you start using it, you’d better first go calculating the course in minute detail – or copy exactly what someone else does (which means that you do not learn to do the planning yourself).
And that’s why I love Mercurial: You start with a simple system and once you are comfortable with it, you activate extensions which make it much more powerful.
In my opinion, git is not efficient to use – except if you are a maintainer or have to use its advanced features all the time.
On the other hand, Mercurial makes you proficient at basic tasks right away – and without studying all kinds of different explanations on the underlying data model. And when you can use it well enough, you just add the capabilities you need.
That’s “Easy to learn, Natural to use, Infinitely extendable”. Essentially it can grow with you.
I’m dubious that mercurial will be natural for me. It’s also clear that it’s very much not natural for some other people.
For example: http://stackoverflow.com/questions/265944/backing-out-a-backwards-merge-on-mercurial (there’s other examples also, but this one’s enough to illustrate why I am nervous).
I will agree that Mercurial is more natural for people moving from SVN than git would be. This I think directly follows from Mercurial’s data model being closer to SVN than git’s data model. But it seems to me that that design choice comes with baggage. If you do not need git’s capabilities, if Mercurial is good enough for you, then that’s fine as long as you will not need those capabilities in the future. But I am dubious of claims that Mercurial is a workalike for git – I see evidence that this is not the case.
I have the same challenge as the poster and there is a simple solution: If you don’t want changes from one branch appearing in the other, you never merge that into the other.
If people do a bad merge, you simply go back before the merge, `graft` all the new commits onto the last good revision and then close the head with the bad rervision. Closing adds a note that this head is obsolete, so people can change to the new head.
Compare this to the situation in git, where someone decided to rebase the remote branch you develop against. Or to undo some change remotely just after you pulled.
PS: Please take note that when you look at this problem, you’re comparing a 4 years old version of Mercurial. Back when people used the transplant extension to copy revisions around (instead of the core command `graft`) and when there was no rebase extension – before hg 1.1 (current is 2.5 → http://mercurial.selenic.com/wiki/WhatsNew ).
I would use git revert rather than git rebase, to undo a bad merge. And I am firmly of the opinion that rebases should be local only – if someone wants to rebase locally that’s their choice, but I would merge their changes and not rebase them (and if the merge is not trivial I’d ask them to fix the problem).
Claiming that the data model of Mercurial is more similar to that of SVN than the git data model is as if you would state that the git datamodel is similar to compressed tape drives. Either you mean the storage layer (in Mercurial that is completely abstracted so it is mostly irrelevant for the user, in git you have to know it to recover from some situations) or you mean the history model (which is the same both in git and hg: You have the state of all files for every revision, revisions have parents and children and you can diff them).
> “if Mercurial is good enough for you, then that’s fine as long as you will not need those capabilities in the future. But I am dubious of claims that Mercurial is a workalike for git”
That sentence actually makes me angry. It is pure FUD and at the same time implies that others said something which they did – and the “dubious” which only applies to the second sentence strengthens the FUD in the first “as long as you don’t need… dubious”.
The first sentence implies that git has capabilities which Mercurial does not have. There is exactly one capability which git has and Mercurial does not: Octopus merges. In Git you can just merge a hundred branches into one revision and commit that. In Mercurial every revision has exactly one parent or two parents, so you would merge them one-by-one (which records the actual history operations you did).
Otherwise Mercurial and Git are feature-equal.
That does not mean, that Mercurial without activated extensions can do all that git can do. Mercurial without extensions has only one destructive history operation and that can only undo the last action. But activating those extensions requires only one line in your ~/.hgrc – or using –config extensions.[name]= in your commandline.
And this does *not* say that Mercurial is a *workalike* for git: It is a different system with different semantics. If you try to use Mercurial exactly the same as you use git, then your workflow will be about as elegant as Python-code written by long-time Java-Programmers.
And why would you *want* a workalike? Git has a clunky commandline and is quite complex to use. And it is free software, so there is no reason to create a workalike. The reason why Mercurial exists is that Git does a bad job at fullfilling the needs of many users (just google “hate git” to find support of that statement).
Just yesterday I saw a statement in Sone (the anonymous social network over freenet) which captures git really well:
> I find git only complicated in practice. In theory it’s simple. — MrJim
I do not know what “more similar” means here.
I was basing my statement on http://xentac.net/2012/01/19/the-real-difference-between-git-and-mercurial.html
I can’t find a reference in that Article how the storage layer of Mercurial is more similar to SVN.
But it directly shows that you have to know the plumbing commands and the data model in git to really use it. An example is using rsync to transfer objects without making them part of the history. In Mercurial you would use `hg incoming –bundle other.bundle other_repo` for the same effect – but abstracted from the storage layer.
You do use extensions and python-code in Mercurial for some things which you do with plumbing commands and direct interaction with the storage layer in Git. But that essentially just says that the plumbing commands in Git along with its data model form a kind of special purpose programming language which builds upon the shell, while Mercurial uses Python as programming language.
If you want to use Mercurial to do the kind of low-level plumbing which git-gurus do with git, you rather fire up a python interpreter and work with context-objects. The barrier to use it is a bit higher. In exchange it is much cleaner and requires much less black magic (in my opinion).
Keeping in mind that I do not know what other people understand the phrase “more similar”, it’s the revlog structure that mercurial uses. Here’s another mention of this issue: http://alblue.bandlem.com/2011/03/mercurial-and-git-technical-comparison.html
From my point of view, having a revlog with an intrinsic order means that the project can’t be truly distributed. I would expect that patches applied to different branches in different orders would result in representation issues when someone tries to represent those branches in the same repository. That said, it’s clear that external tools can be used to address at least some of these issues.
Anyways, looking at the comments here, about why mercurial is superior, have to do with the enforcement of a linear order for changes – this seems to be a reflection of the revlog data structure. But enforcement of a linear order describes svn, also. And the complaints about git rebase (mercurial collapse and histedit plugins) seem to me to be complaints about the absence of this enforcement.
[Hopefully I have not been too casual, here, with my use of technical terms. There’s a variety of ways of describing revlog, and there’s a variety of techniques that can be used to work around issues in some circumstances. So any casual description will necessarily not touch on all of the possibilities and will miss out on things that some people think are significant.]
What do you mean by “enforcement of linear order for changes”? (I seem to only be asking at the moment :( )
I don’t see any reason why you should enforce a linear order of changes in Mercurial.
Why should the storage layer affect the history at all? You can transparently map all history operations of Mercurial onto git – and vice versa.
The revlog is just like packfiles in git – but done on-the-fly while storing the commit instead of requiring a separate packing step (which in git by default is called at regular intervals to avoid fluctuation of repository size by more than factor 4 – at least that’s what my tests showed).
Imagine what would happen if you had append-only-packfiles in git which would automatically compress and store new commits when you make them. Would that make git less decentral?
Btw.: The reason why Mercurials storage layer uses a file-based structure is that this exploits an optimization in filesystems: Getting the changes from the storage files in the same order as the files in your working copy to avoid unnecessary disk-seeks. You can actually notice that when you listen to your hard disk while doing bigger operations with git and hg: Git makes your disk stutter loudly while with Mercurial it stays silent.
“What do you mean by “enforcement of linear order for changes”?
…
Why should the storage layer affect the history at all?
…”
I mangled the concepts when I choose those words. After looking closer I now think that the important distinction has to do with how content and changes are identified, and it also has to do with which operations are atomic (which matters when we think about “what happens when things go wrong”). There are some linear assumptions here (as indicated by your next quoted paragraph, below) but I do not know enough about the data structure to know if there are any specific consequences from those assumptions.
“Btw.: The reason why Mercurials storage layer uses a file-based structure is that this exploits an optimization in filesystems: Getting the changes from the storage files in the same order as the files in your working copy to avoid unnecessary disk-seeks. You can actually notice that when you listen to your hard disk while doing bigger operations with git and hg: Git makes your disk stutter loudly while with Mercurial it stays silent.”
I mostly use solid state storage, so I can’t hear any disk stutter.
With Mercurial you have append-only files with journaling (if you use hg rollback, you essentially just roll back the last journal entry). It uses locking for write-access, but not for read access.
There once were some linearity assumptions in the compression scheme of the store, but they are gone since parent delta was implemented (store the delta to the parent revision, not to the previously saved one).
I still clamsy with git. But mercurial… It’s use comes very natural to me right from the first strokes of it’s command line interface.
Hey there just wanted to give you a quick heads
up. The text in your article seem to be running off the
screen in Firefox. I’m not sure if this is a format issue or something to do with internet browser compatibility but I figured I’d
post to let you know. The design and style look great though!
Hope you get the problem solved soon. Thanks
It’s a pity you don’t have a donate button! I’d certainly donate to this excellent blog! I suppose for now i’ll settle for
book-marking and adding your RSS feed to my Google account.
I look forward to fresh updates and will talk about this
site with my Facebook group. Talk soon!
Learning to Code | Quartet
Learning to Code | Decluttr
Well Said mate, There are lot of people who talk about GIT very high, without even using it on real projects.
GIT: a Nightmare of Mixed Metaphors | Right Brain Programmer on Mars
very good
دانلود فیلم http://www.2.2film40.in/
I want my Version control system to allow me to put my code in a central repository so that my team mates see the changes I have made. And then get out of the way. I have to concentrate on programming, and not bother with git and its metaphors.
I guess I am glad that people like you exist. (Having competition who consistently write poor use cases makes my life so much easier.)
This is by design, you know? Git is a low-level ‘content-tracking’ tool and you look like a hacker from 90ies movies when you run simple operations. As they say, here http://svnvsgit.com/#git-leaky-abstraction **Git has leaky abstraction and crazy command line syntax**! It is not easy or simple at all.
I was recently involved in a contract where the source code was so bad, I believed the company could easily become criminally negligent. I was continually astonished at the lack of integrity of the git repositories and am seriously wondering if the use of git could seriously harm a company’s defense in a negligence lawsuit.
(Beyond that, the very nature of distributed version control creates an IP nightmare for the company.)
though given that `hg convert ` instantly gets the whole subversion history, the IP nightmare always existed :)
hg convert ANY_REPO NEW_HG_REPO
Linus hates NVIDIA because they are still using svn and refuse to switch to git.
Linus hates NVIDIA, because they force their buyers to use a proprietary kernel module which locks the users into specific kernel versions.
Ah! The plot thickens.
Good article and debate. I heard how good git was and liked the concept and fact that it solved issues which other source control systems have. That really is needed and its a shame that git has been made so complex to get an improvement.
The argument that its complicated because its distributed doesn’t stack up for me. We need people to be able to work independently and merge changes and that is true with or without the distributed nature. Why is that so hard when the base concepts are relatively simple and should be intuitive.
With many unix things they are very clever and designed for “clever” people to work with. So with anything originating from that world it is expected that you have to prove your capabilities before you can progress to the next level. Like a computer game. This is why VI is still a prominent editor, and many people argue its merits; so its no wonder why git is what it is.
The GUI that I have used, source tree, isn’t helping as it isn’t simplifying enough. Maybe a better GUI could solve things.
NextStep and then Apple have done a good job of hiding the complexity of unix and making it usable for people who can’t be bothered with cryptic crosswords. So it ought to be possible to simplify concepts and have a better GUI for git.
To help with me git grappling I was recommended an article which explains in detail how git works. That says it all. Whatever happened to abstraction – its interesting how it works, but I shouldn’t have to know that in order to use it.
I guess I said it before in here, but still: There is an easier UI with the same power. It is called Mercurial.
I think that writer of this article is right. Git is a patological disease , an example of computer science calamity and is slowdown software development in this third millennium. Never such a high fraction of people has being chatting about source code management instead of design and having new ideas made real for the final user.
Subversion vs. Git: Myths and Facts > Seekalgo
Git and SVN | David Albert
为什么你应该使用 Git 进行版本控制 | 编程案例分享